
No começo de junho rolou o
Darkmira Tour 2019, lá em Fortaleza.
Infelizmente, não consegui estar presente, mas na edição do ano passado tive
esse imenso prazer. O evento aconteceu nos dias 14 e 15 de abril de 2018, em
Brasília. Contou com mais de 20 palestrantes e alguns painéis. Acabei
encontrando recentemente minhas anotações no fundo do baú editor de texto,
então nesse post vou tentar dar uns highlights do que vi por lá, espero que
gostem!
Você é um bom dev? - Diana Arnos ¶
Abrindo o evento, temos o keynote da Diana Arnos, que é uma das evangelistas do PHPWomen. Ela começa a talk com um comparativo entre júnior e sênior.
Júnior vs Sênior ¶
Ela diz que tem júnior que aprende muito rápido ao passo que existe sênior que "caga" regra. A Diana já teve a experiência de entrevistar alguns devs que se diziam sêniores mas que não sabiam muitas coisas básicas e, nessa, não eram aprovados na contratação. O que mais diferencia um profissional na opinião dela é a resolução de problemas. Um júnior tem a vontade de desenvolver, aquele desespero de não saber nada mas tentar correr atrás de todo mundo para resolver. Já um sênior tem uma tranquilidade maior e consegue investigar os problemas com calma, seguindo um passo a passo e chegando até a resolução sem maiores exaltações.
Boas práticas ¶
Por que se preocupar com boas práticas? PSRs, Calisthenics, etc. Segundo a Diana, utilizar boas práticas indica quão longe você foi no conhecimento da linguagem e diz muito sobre você, sobre aproveitar o potencial das ferramentas e linguagem. Ela também comenta sobre o ciclo de vida de um software, citando até as culturas Agile e DevOps.
Saiba preparar o seu ambiente ¶
Você sabe como sua aplicação sobe? Ou você só executa um script que algum DevOps do time te mandou? É importante conhecer o sistema operacional, as ferramentas do servidor, mesmo que apenas superficialmente.
Virtualização é uma ótima forma de saber isolar as dependências da sua
aplicação e garantir que seus projetos não afetem seu ambiente local. Você pode
usar Virtual Box, PHPansible, Docker... (só não subam o docker como root, por
favor! - ela apela)
Controle de Versão ¶
"GIT! Quem usa .zip merece morrer." - Utilize o Git ou qualquer outra
ferramenta de controle de versão. Você terá acesso a histórico, poderá reverter
códigos que já foram feitos, poderá ter uma documentação do que foi feito e, de
quebra, tem um backup da lógica da sua aplicação.
"É sabendo de onde vem que sei pra onde vai"
Segurança ¶
A Diana comenta que qualquer informação que você expõe do seu sistema está abrindo a potenciais falhas a serem exploradas. Não use IDs sequenciais para mostrar aos usuários. A coluna de ID do banco serve única e exclusivamente para o banco. Não exponha essa informação ao usuário. Não mostre a assinatura do servidor e da linguagem nas requisições, é muito fácil desabilitar isso e evita que algum potencial atacante tenha de mão beijada que você está rodando por exemplo nginx numa versão específica. Inputs devem ser validados e, não, não estamos falando de validar (somente) no frontend, devemos validar os dados do lado do servidor. Utilize também Argon 2 e libsodium que o PHP tem suporte.
Ferramentas ¶
A Diana reuniu em um slide algumas coisas que citou: Linux, Windows, Git, GitHub, Virtual Box, Docker, Gecko, WebKit, Terminal, nginx, Apache, Ansible. E que devemos nos lembrar que é muita coisa para se dominar além do desenvolvimento em si e não necessariamente um júnior ou um estagiário possuem esse conhecimento.
Dicas ¶
DURMA, não fique acordado de madrugada resolvendo problemas. A neurociência é sua amiga. Quando você dorme, seu organismo consegue limpar as toxinas acumuladas no seu cérebro. Esqueça desse status de que você é um dev "foda" porque ficou varado trabalhando.
Ainda em neurociência, o pensamento focado é o que já estamos acostumados, que usamos para resolver problemas que já conhecemos e sabemos como atacar. Caso estivermos em um problema que não sabemos resolver, podemos relaxar, ir tomar um banho, um café e deixarmos o pensamento difuso agir, resolvendo os problemas através da ligação de informações que talvez não fizessem tanto sentido no pensamento focado.
A prática cadenciada, como por exemplo, estudar todos os dias por 30 minutos, é algo muito benéfico que até muda nosso cérebro.
Open Source ¶
Como última dica ela diz: faça open source!
Confira os slides no SpeakerDeck.
Investigando a saúde de seu sistema através de Logs - Raphael de Almeida ¶
Após o keynote da Diana e o coffee-break/networking, escolhi ver a talk do Raphael, já que contamos com duas trilhas no evento. Ele é community manager do PHPRio e veio falar sobre logs. Ele começa citando Murphy:
"Qualquer coisa que possa dar errado, dará no pior momento possível."
Edward A. Murphy
E diz que quanto mais tempo um sistema fica inconsistente, piores são as consequências.
Quem nunca desabilitou os logs do PHP e do Apache porque eles enchiam o disco do servidor? - brinca Raphael. Erros no sistema deixam o usuário frustrado em relação à aplicação, podendo até fazer o mesmo desistir do uso por uma percepção de baixa confiabilidade.
Entre problemas de saúde do sistema, o Raphael cita alguns casos:
- Ter inconsistência de dados é um problema que nossa aplicação pode sofrer mas, num exemplo de um e-commerce, um preço muito fora da média poderia ser detectado automaticamente.
- Caso ocorra a exposição de vulnerabilidades, como um log de erro do de uma query MySQl exposto, um atacante conseguiria coletar informações e montar o ataque contra o sistema.
Quando algum problema ocorrer, reproduza o erro em ambiente local ao invés de ficar fazendo em produção, tenha o ambiente local o mais próximo possível do ambiente de produção. Aquela história de "na minha máquina funciona" pode realmente acontecer, mesmo com o ambiente parecido. O problema é que o contexto específico em que o bug aconteceu pode estar faltando. Por isso, um log é um diário de acontecimentos que pode nos dar insights sobre o contexto em que a aplicação vive.
Uma dica para fazer logs é escrever uma boa mensagem de erro, não faça por
exemplo um log escrito "Erro inesperado". Para escrever uma mensagem relevante
é necessário que o desenvolvedor tenha experiência, aprenda com quem está
acertando na escrita e evolua seus logs. Banco de dados, por exemplo, utilizam
códigos de erro para facilitar a pesquisa de soluções.
Os erros do PHP são muito bons para descobrir que problemas estamos enfrentando. Similarmente, os erros de framework contêm bastante informações relevantes. Já os códigos de erro HTTP geralmente são ambíguos então uma dica que o Raphael dá é não espelhar esses códigos HTTP para explicar o contexto de erros dentro da aplicação.
Contexto dos erros ¶
Quando e onde aconteceu o erro? Se temos mais de uma máquina, qual o ambiente e o nome do host? Com o contexto certo, poderemos saber exatamente qual equipe é responsável por resolver aquele problema.
É uma boa ideia salvar informações sobre o usuário logado, primary keys, stacktrace, arquivo e linha onde o erro ocorreu, a requisição HTTP.
Seus logs precisam ser de fácil pesquisa e agrupamento.
Utilize os níveis de criticidade dos Logs, que vão desde DEBUG até
EMERGENCY, seguindo por exemplo o
RFC5424 - The Syslog Protocol,
utilizado pelo Linux.
| Nível | Criticidade | Uso indicado |
|---|---|---|
| DEBUG | Menos crítico | Mensagem para ajudar na depuração |
| INFO | . | Eventos comuns |
| NOTICE | . | Eventos comuns, porém com certa relevância |
| WARNING | . | Eventos que merecem uma certa atenção |
| ERROR | . | Erros em tempo de execução |
| CRITICAL | . | Falha de serviços externos ou módulos |
| ALERT | . | Falha que precisa de ação imediata |
| EMERGENCY | Mais crítico | Sistema está fora |
No PHP, temos o PSR-3, que é seguido, por
exemplo, pelo Monolog. Também temos as
exceções nativas do PHP, que seguem uma hierarquia e podem ser muito
úteis para as tratativas da nossa aplicação. Em produção, não devemos mostrar os
erros, configurando adequadamente o php.ini, por exemplo da seguinte forma:
display_errors = Off
error_reporting = -1
log_errors = On
error_log = /var/log/app_error.logPodemos posterior fazer uma análise desse log com tail:
tail -f /var/log/app_error.logIsso funciona bem quando temos apenas um servidor, porém para mais de uma máquina devemos agregar esses logs em um único local. Podemos usar uma ferramenta como o Splunk, por exemplo. Outra é o Kibana, que junto com o Elasticsearch e o Logstash forma um ecossistema para análise e até mesmo predição de erros. Outras opções também incluem oGraylog e o papertrail.
Dicas ¶
Antecipe problemas analisando seus logs, com notificações que podem vir por slack, telegram, email, etc. Separe as responsabilidades para atribuir e identificar erros corretamente. Tenha rotinas para ver logs não críticos. Faça testes para reproduzir bugs e garantir que eles não aconteçam mais. Entenda que você pode ter problema de recursos, indisponibilidade de bancos de dados, rede, sistema de arquivos e tente preparar sua aplicação para pelo menos exibir mensagens de erros coerentes nesses casos. Existem erros provocados por ataques e também por usuários, que só estão tentando utilizar o sistema. Queries lentas também devem aparecer em logs, para que possamos atuar sobre elas.
Clique aqui para ver os slides da apresentação do Raphael.
PHP + Docker + ELK + React: Um case de sucesso - Rodrigo Régis Palmeira ¶
O Rodrigo, ou melhor, o Régis, é chefe de desenvolvimento do Tribunal de Contas do Distrito Federal (TCDF) e trouxe o case que ele participou no trabalho. Em meados de 2017 foi levantada a necessidade de uma melhoria no sistema de pesquisa textual do TCDF. O sistema de pesquisa já existente utilizava full text search do SQL Server. Embora funcionasse, a busca existente era limitada. O que os usuários pediam, basicamente, era uma busca similar a do Google. Ao analisar a possibilidade de se utilizar a ferramenta Google Search Appliance, o custo seria de 2,5 milhões de reais apenas para a configuração que eles precisariam, sem contar outros custos. Parecendo inviável, foram atrás de outras soluções, estudando como outros governos estavam fazendo suas buscas até chegar no Elasticsearch.
Assim, decidiram fazer uma implementação definindo que as tecnologias utilizadas seriam todas open source. Uma delas é o Apache Tika, que extrai dados relevantes, como o texto, de diversos formatos de arquivos como imagens, PDFs, etc. Os dados extraídos pelo Tika são enviados para o Logstash, ferramenta da Elastic que recebe dados brutos, filtra, transforma e solta uma saída mais rica. Essa saída é então enviada para o Elasticsearch, onde os dados são armazenados e podem ser pesquisados com queries e outras diversas facilidades. Por fim, o Kibana é uma interface plugável no Elasticsearch para pesquisas e que pode ser utilizado diretamente pelos usuários, por exemplo.
No backend dessa implementação, eles utilizaram, entre outras coisas, Symfony, Guzzle e Doctrine. Já no frontend, decidiram por React com JSX. Também decidiram adotar o Docker, que traz portabilidade, versionamento, uniformidade, imutabilidade e diversas outras vantagens para o ambiente de desenvolvimento e também para o de produção.
O ecossistema anterior de busca tinha basicamente PHP com Apache no sistema principal, banco SQL Server, um outro sistema para controle de acesso com PHP, Symfony, Apache e um servidor para salvar e recuperar arquivos com as mesmas tecnologias, juntamente com o Samba.
Depois do desenvolvimento do novo ecossistema, que foi feito pelo Régis e outro colega de trabalho, agora existem interfaces com APIs, tanto para o sistema principal quanto para a busca. Também existem máquinas para a busca dos usuários, máquinas para Logstash e Kibana, Elasticsearch, sendo a maioria delas dentro do Docker e usando NGINX ao invés do Apache.
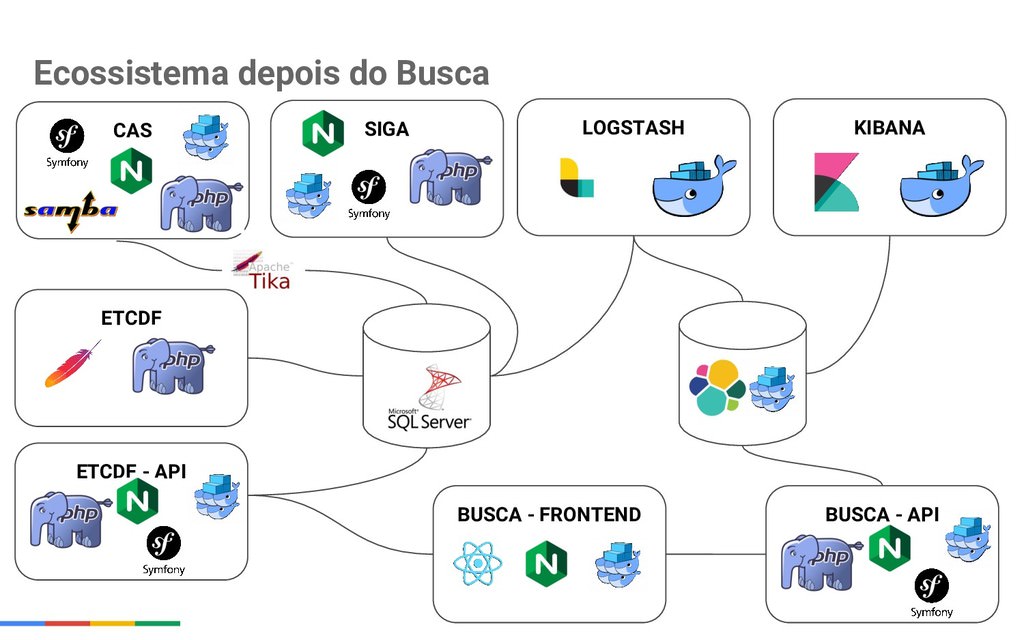
O projeto foi colocado no ar em dezembro de 2017, com uma interface muito próxima a do Google. O feedback dos usuários foi muito positivo, com uma busca agora muito mais completa e assertiva, sendo um belo case de sucesso desenvolvido em apenas três meses, com um orçamento bem reduzido. O Régis ressalta que iniciativas de governo como essa devem ser mostradas.
Em seguida, ele mostrou alguns dashboards feitos no Kibana para uso interno, servindo também como ferramenta de monitoria. Também abriu a busca ao vivo e mostrou seu funcionamento.
Como próximos passos, eles percebem a necessidade da criação de um dicionário de sinônimos no Elasticsearch, uma autenticação com JWT e LDAP para pesquisas restritas de uso interno, com sigilo. Outro passo é a de fazer a busca ser um PWA (Progressive Web App).
Clique aqui para conferir os slides da apresentação.
Stand-up do Pokemaobr ¶
Na volta do almoço, a pedidos da "comunidade", o pokemaobr fez mais um de seus ótimos stand-ups sobre a incrível vida de DEV. Eu sempre choro de rir, pois me relaciono demais com as piadas que ele faz.
On Being a Senior Engineer - Sheeri K. Cabral ¶
Em seguida tivemos mais um keynote, dessa vez com a Sheeri que é Senior Database Engineer e MySQL Community Contributor. Ela comenta que vai falar mais ou menos sobre o tema que a Diana abordou, porém de uma forma um pouco diferente.
Níveis de senioridade ¶
Quando falamos dos níveis de alguém, Júnior, Sênior, etc., de forma básica, os colaboradores executam processos de escrita, criam novos processos e os executam, tomam a iniciativa numa tarefa, lideram um projeto, fazer a arquitetura de algo. O trabalho que fazemos pode ser em projetos pequenos, em grandes projetos, pode envolver liderança, participação, fazer parte nas especificações, etc. Autonomia é algo que difere um pouco entre os níveis.
É muito importante ser parte de um time, então em muitos casos é muito bom ter um par para revisar seu código, principalmente quando se é júnior. A Sheeri ressalta que mesmo um sênior pode ter seu trabalho revisado, pois todos são passíveis de erros. Duas cabeças pensam melhor que uma.
Priorização ¶
Algo que sêniors fazem é priorizar o trabalho. Já júniors acabam pedindo uma priorização e cronogramas para relembrá-los. Um sênior meio que "sabe" quais são as prioridades, se atacar a menor tarefa ou a maior, etc. Ele também sabe alinhar essas prioridades com outras pessoas/departamentos. Algumas níveis de expectativas que existem quando vamos desenvolver:
- vou escrever código seguro
- vou implementar o módulo de encriptação
- vou implementar o módulo de encriptação pelo fim de maio
- vou perguntar o prazo da tarefa e alinhar as expectativas
Quando priorizamos, devemos dizer não. Porém, existem vários tipos de não que um sênior aprende a dizer. "Não posso fazer isso agora, mas é possível para o fim do mês". "Não posso fazer agora, mas vamos ver se alguém da equipe pode fazer". Ainda é um não mas é um não que consegue ser útil e prestativo e que busca ajudar na resolução da mensagem.
Analisando e assumindo riscos ¶
É importante desenvolver um senso apropriado de risco, tanto para você quanto para a companhia. Por exemplo, será que compensa fazer um deploy depois das três da tarde em um pré-feriado? Devemos pesar consequências, fazer testes e ter um plano rápido de rollback, mesmo que isso signifique ter mais trabalho depois.
Detalhes versus Quadro Geral ¶
Devemos fazer o trabalho; entender o impacto do trabalho para a empresa; entender porque o trabalho está sendo feito; sugerir objetivos; sugerir a visão; escolher os objetivos/visão.
Recomendações ¶
Pense sobre tecnologias, na capacidade do time em relação a elas e no "fit" na organização. Não queira usar apenas a "nova tecnologia para testar/aprender". Uma ressalva é que aqueles com experiência algumas vezes acabam usando algo antigo que eles já tem maior familiaridade. Defenda pontos quando necessário. Entenda quando é preciso resolver algo no mesmo momento, quando não compensa resolver e quando podemos simplesmente escrever um ticket para resolver depois. Aplique a regra do 80/20.
Balanço: O que é melhor? ¶
Algumas vezes a solução técnica "correta" não é a solução ótima para o ambiente. Por outro lado, algumas vezes você vai contra uma melhor prática porque é a coisa certa a se fazer. Tecnologia baseada em consenso: quando todos vão para uma sala e saem com uma decisão que nem todos podem concordar, mas que é a melhor e que todos assumem e adotam.
Escopo ¶
No trabalho, seu escopo e impacto pode ser pequeno ou grande. Você pode trabalhar com mais pessoas ou sozinho, pode trabalhar com mais times, trabalhar com clientes ou não.
Trabalho "Real" ¶
O trabalho em si nem sempre envolve código ou linha de comando. Existem reuniões, expectativas, definições de pronto. Há também muito planejamento. Seu trabalho também pode envolver planilhas, software de planejamento de projeto, groomings, documentação e aprovação.
Relacionamentos ¶
Você trabalha com outros para obter resultados. É imprescindível boa comunicação, alinhamento das expectativas e acompanhamentos para certificar-se que tudo ocorre como esperado. Falar sobre seus hobbies, o que você fez no final de semana, etc. Existe um balanço sobre não trabalhar e ser 100% focado no trabalho, encontre o seu.
Comunicação ¶
Comunicação depende da sua audiência, você deve saber comunicar as coisas de acordo com o público, por exemplo, usando ou não termos técnicos, contextualizando para o entendimento de quem está presente. Saiba com quem está conversando.
Respondendo a uma questão ¶
Existem várias maneiras de se responder a uma questão. Por exemplo, para a questão: "Como eu posso fazer o DB usar um índice nessa query case-sensitive?", você poderia responder:
- "Eu não sei."
- "Você não pode fazer isso."
- "Você poderia tentar isso, ah, pera, isso não funciona.Você poderia tentar isso aqui... ah, não funciona também..."
Melhor do que isso, você poderia dizer: "tente isso e vê se funciona" ou "eu testei isso e funciona". Ou melhor ainda: "que problema você está tentando resolver?" - Pense sobre quem está fazendo a pergunta e como pode verdadeiramente ajudar.
Reputação ¶
Pessoas percebem você como um expert, não importa o que o seu cargo diga. Reputação é sobre relacionamentos. Você trabalha com pessoas, portanto é importante se dar bem com elas e isso reflete diretamente em como elas o vêem. Confiança também é importante: poder confiar que vai realmente fazer o que foi combinado. Faça um bom trabalho, mesmo em casos que pensa que estão além de você. Ajude os outros.
Dicas e segredos ¶
Desenvolva relacionamentos, agradeça às pessoas que fazem o trabalho para você ou com você. Se um grande projeto terminar ou alguém sair da empresa, deixe um review legal no LinkedIn. Faça com que seja fácil para os outros fazerem o trabalho que você precisa que eles façam.
Infelizmente não consegui acessar os slides no momento da publicação desse post, mas estou tentando.
Serverless: Função como serviço em PHP - Jonata Weber ¶
O Jonata, que era da Bahia e está por perto, em Goiânia, foi falar pra gente sobre Serverless, citando um artigo que foi onde ele teve contato com o tema, onde o autor afirmava que para cada 30 mil requisições pagava apenas US\$0.21. Ele afirma que o termo "Server-less" é um pouco estranho pois existem servidores em algum lugar, então alguns termos um pouco melhores seriam "No Ops", "No Internal Sys Admin", "Service-full" Architecture... enfim.
O movimento serverless tenta abstrair e facilitar muitas coisas do processo de desenvolvimento de software, visando tornar mais fácil colocar código em produção. Ele cita o time to value: intervalo entre identificar um problema e entregar valor e diz que quanto menor esse tempo, melhor vai ser para o sucesso do projeto.
Para rodar um app, precisamos de um Sistema Operacional (SO), que por sua vez precisa de um hardware. Como devs, gostamos de abstrair as coisas e, assim, começamos a trabalhar com máquinas virtuais, que abstraem os sistemas operacionais, sem precisar lidar diretamente com hardware e rodando o app em "qualquer" servidor.
Seguindo em uma linha mais profunda de abstração, temos o BaaS (Backend as a Service - Backend como um Serviço), que abstrai o backend todo e te dá apenas APIs para lidar com a aplicação, lidando com banco de dados e diversos outros problemas. Abstraindo mais ainda, temos o FaaS (Function as a Service - Função como um serviço), onde funções vão rodar por exemplo em contêineres, com um input e um output.
Empresas que suportam FaaS incluem: AWS, Google Cloud Platform, Microsoft Azure, Apache OpenWhisk. O Jonata cita que só o Azure suporta PHP. Logo em seguida, ele faz uma demo mostrando um pouquinho dos conceitos do FaaS.
Para a talk, ele preparou um exemplo de BaaS + FaaS para guardar likes de posts no twitter, enviando esses dados com o Apache OpenWhisk, que consequentemente os salva no Firebase, mostrando em tempo real as atualizações numa interface de usuário. A aplicação de exemplo está disponível no GitHub.
Para finalizar, o Jonata faz um paralelo com o mais tradicional PaaS (Platform as a Service - Plataforma como um Serviço) mostrando que você paga de forma diferente por esses serviços e que no PaaS provavelmente seu servidor tem um tempo ocioso.
Vantagens ¶
Entre os benefícios de se utilizar tecnologias do tipo, temos um custo menor com Dev e Ops com BaaS. Já com FaaS, contamos com auto-scaling e pagamentos apenas pelo uso. Com essas tecnologias temos mais facilidade em atingir o time to value, podendo fazer mais experimentação. Contamos com uma complexidade reduzida de build e deploy (por exemplo, é só alterar uma função onde foi identificado um problema, ao invés de fazer o deploy do sistema todo). Ainda contamos com zero administração.
Desvantagens ¶
Já, pelo lado ruim, temos grande latência de inicialização; limitação de tempo de execução do contêiner; repetição de lógica em alguns casos e dificuldade de testar a aplicação.
Futuro do Serverless e Possibilidades ¶
O Jonata vê o serverless tendendo para uma evolução no ferramental, inclusive para testes. Também espera que ocorra o surgimento de padrões, entre outras coisas. Ele acredita que Serverless serve para aplicações web; como backend de IoT (internet das coisas); como backend de aplicações móveis, entre outros usos. Por fim, cita um artigo do Martin Fowler sobre o tema.
Infelizmente, não consegui encontrar os slides da apresentação.
API First: Quando utilizar a estratégia de API? - Bruno Souza ¶
O Bruno Souza, que trabalha no Itamarati, veio falar sobre APIs, tema que teve um boom nos últimos tempos. Uma API é uma coleção de rotinas, protocolos e ferramentas para "construção de plataformas". Na talk dele, ele decidiu falar sobre WebAPIs.
WebAPIs são baseadas na arquitetura cliente x servidor e podem servir pra várias coisas, por exemplo:
- como um gateway para gerenciamento do controle de acessos;
- como um contrato entre consumidor e provedor de APIs;
- permite a integração de apps e dispositivos;
- permite a criação de apps com base em outros apps;
- como um plug-in universal;
- como um filtro de segurança;
A economia de APIs envolve por exemplo IoT, para gerenciar os dados do dispositivos. APIs tornaram possível a criação de FinTechs mais dinâmicas como os bancos Nubank, por exemplo. Dentro de criptomoedas, as APIs são vitais. Redes sociais também fazem uso de APIs.
Com isso, chegamos ao conceito de API First, que tem o intuito de alinhar a criação de APIs com os objetivos de negócio. A estratégia envolve pensar primeiramente na API, antes mesmo da implementação. Ela deve ser a primeira interface de usuário da aplicação e deve ser bem descritiva.
Segundo o Bruno, os benefícios são múltiplos: integração de vários dispositivos; ambiente distribuído; criação, manutenção e refatoração das funcionalidades em API bem documentadas. Melhora a produtividade do time, até sendo mais aderente ao ágil.
Uma arquitetura baseada em API visa centralizar diversos recursos e serviços em um lugar só onde os clientes se conectam. Uma API agrega valor promovendo novos negócios, experiências e recursos; monetiza ativos; oferece suporte a vendas e marketing; organiza códigos e estruturas monolíticas.
Quando usar uma estratégia de API? Para saber disso, algumas perguntas que precisam ser respondidas são:
- Qual a principal razão para a criação da API?
- Quem é o público de desenvolvedores?
- Quais ativos serão disponibilizados?
- Que tipo de aplicativo pode ser criado?
Mobile First versus API First ¶
No Mobile First, a prioridade do planejamento do desenvolvimento se dá a partir de dispositivos móveis. Já no API First, a API é construída primeiro. Essas abordagens permitem que várias plataformas sejam construídas.
Temos também a API voltada para a Developer Experience, onde o foco da criação da API é na UX (sendo o desenvolvedor o usuário). Como os desenvolvedores usarão essa interface? É importante definir o tipo de dev que usará a API, expor os objetivos dela com clareza.
Prototipar sua API é muito importante para melhorar o design da mesma. Algumas ferramentas que auxiliam nesse processo são: Apiary, RAML e Swagger. A documentação da API auxilia muito a equipe no momento do desenvolvimento e atualização da mesma. É importante que a documentação seja fácil de entender e pesquisável, sendo auto-suficiente e intuitiva. A mesma deve estar sempre atualizada.
Podem existir APIs públicas e privadas, cada uma com o seu intuito. Independente disso, devem ser consideradas medidas de segurança, como por exemplo, autenticação e autorização. O tráfego da mesma pode ser monitorado, com controles como limite de requisições, cotas de uso, rejeição de requisições, etc.
Arquiteturalmente falando, contamos com alguns padrões como por exemplo SOAP, REST e GraphQL. O Bruno explicou um pouco como funciona cada um desses padrões, com alguns exemplos básicos.
Ele ainda falou que é importante pensar em performance, para que a API responda em tempo hábil e seus usuários não percam o interesse na aplicação. Mostrou também que existem algumas ferramentas para realizar testes da API. Como conclusão, explicou como uma API traz grandes oportunidades de negócio, tendo os desenvolvedores mais alinhados com os objetivos. Os pré-requisitos para criação de uma boa API são:
- Alinhar os objetivos de negócio
- Estabelecer os perfis dos desenvolvedores
- Definir a arquitetura da API
- Implantar uma infraestrutura de API
Até a publicação desse post, não encontrei os slides da apresentação.
The QueryFilter Concept for Filtering Models - Junior Grossi ¶
Para finalizar o primeiro dia de palestras, decidi ver a talk do Junior, um dos
organizadores do PHPMG. E após se apresentar, ele explicou que QueryFilter é
uma abstração para filtrar objetos baseado nos parâmetros da URL. Ele diz que
pegou a ideia de um vídeo do Laracasts. Explicando o
conceito, caso quiséssemos pegar posts com título foo e status bar,
poderíamos utilizar uma URL do tipo:
/posts?title=foo&status=barE essa é mais ou menos a ideia do QueryFilter. Logo já partimos pro live
coding, que foi bem completo e explicativo - o Junior é um ótimo professor.
QueryFilter é um conceito, podendo ser utilizado em qualquer linguagem.
Existem alguns pacotes prontos para isso disponíveis no Packagist, como o
cerbero/query-filters e o
kblais/query-filter que podem ser
utilizados nos seus projetos. O Junior comentou que inclusive utiliza o
cerbero em seus projetos.
Confira os slides da apresentação no SpeakerDeck.
Dia 2 ¶
ChatOps! Como Podemos Usar "Chatbots" Para Realizar O Trabalho De Infra Por Nós - Rodrigo "Pokemao" Cardoso ¶
Como cheguei atrasado no evento (ops! 😅), essa foi a primeira talk do dia para mim. O pokemaobr, Community Manager no iMasters e criador do PokePHP, veio falar sobre um case específico de uso de ChatBots, para Ops.
ChatBots existem desde 1950, porém viraram moda atualmente. O pokemao comenta
que já fazia ChatBots no mIRC, anos e anos atrás. Esses bots são bem parecidos
com os de hoje: funcionam em um chat, orientados a eventos e expressões,
permitem a execução de comandos, possuem acesso a serviços externos, têm
integração com base de dados (arquivos .ini) e "inteligência artificial". Mas
por que ChatBots estão na moda? Um dos motivos talvez seja a ideia que é vendida
de que eles podem resolver todos os problemas de atendimento. O pokemao
considera isso um mito e também cita outros mitos, como falar que os mesmos são
inteligentes e que as pessoas preferem falar com robôs.
Com serverless por exemplo, é fácil fazer um bot com um custo baixo. Além disso, existem várias soluções com cotas gratuitas. O legal de chatbots é que você consegue implementar em qualquer linguagem, integrando aos serviços através de APIs ou com SDKs.
Aproveitando o que temos de bom em chatbot, que são os comandos, o pokemao chega ao tema ChatOps. Num fluxo básico de ChatOps, um desenvolvedor envia uma mensagem num aplicativo de chat, que é lida por um bot e alguma ação é realizada na sua infraestrutura.
É possível, por exemplo, criar e destruir novos servidores em cloud, utilizar automatizadores de criação de ambientes como Ansible, Chef, Puppet. Com as APIs e SDKs existentes, isso se torna viável com ChatOps. Outro problema que pode ser resolvido é o de Deploy.
Alguns projetos citados foram o Hubot, do GitHub; o Slack Deploy Bot; o opsdroid; o Botman, feito em PHP e por último o repositório Awesome ChatOps.
Em seguida, o pokemao mostrou como fazer um ChatOps Bot na prática com PHP para
resolver o problema de criar e deletar droplets na Digital Ocean através do
celular. Ele utilizou a biblioteca
Digital Ocean V2, a ferramenta
Dialogflow onde é possível definir intenções do
usuário, como por exemplo, "listar droplets". Essa ferramenta permite que
webhooks sejam acionados de acordo com intenções pré determinadas. O pokemao
fez uma live mostrando na prática a criação de um droplet chamado darkmiratour
pelo Telegram. Num outro exemplo mostrado, utilizando o
TelegramBot/API, o pokemao fez uma
ferramenta que verifica se determinado site está online e avisa por Telegram
caso o site saia fora do ar.
Os slides da apresentação estão disponíveis no SpeakerDeck.
Painel Das Comunidades ¶
Em seguida, tivemos um painel com diversos organizadores de comunidades conversando sobre os desafios de se manter uma comunidade e o trabalho que cada uma faz, muitas vezes até social, como no caso do PHP com Rapadura. Fui convidado a participar por conta do meu trabalho (meio parado no momento, eu sei 😕) na comunidade do @laravelsp. Foi um momento interessante para apresentar aos participantes essas comunidades e também dar dicas de como ajudar ou criar sua própria.
Compartilhando Conhecimento E Unindo Uma Equipe Por Meio De Code Review - Vinícius Alonso ¶
Na volta do almoço, decidi ver a talk do Vinícius, que tratou do tema Code Review (Revisão de Código). Ele começa com a definição:
Code Review é uma prática de revisão de trabalho de um programador antes de integrá-lo a base de código.
E cita os valores dessa prática: com o review, temos o compartilhamento do conhecimento. Centralizar o conhecimento em apenas um membro pode ser prejudicial à equipe. O review também promove o debate das soluções, que pode ser ótimo para melhorar nosso código. O senso de equipe aumenta.
Papéis dos envolvidos ¶
Temos o autor, que é quem escreveu o código e enviou o Pull Request. Entre suas responsabilidades, deve escrever código de qualidade, resolver o problema de acordo com o requisito, fornecer contexto, não introduzir nenhum defeito...
Temos também o revisor, que deve instigar um debate sobre o trabalho do colega por meio da argumentação lógica. As responsabilidades do revisor envolvem perguntar, não dar ordens, justificar as melhorias propostas, ajudar com correções e mudanças.
Pontos chave para fazer um review de qualidade ¶
- O que foi desenvolvido atende aos requisitos? É importante cuidar para não introduzir defeitos e de preferência não fazer tarefas ocultas no PR (Pull Request), que podem deixar a tarefa muito mais demorada ou complexa. É interessante separar os Pull Requests por tarefa, caso deseje fazer alguma outra coisa, faça outro PR e deixe claro para o time.
- Os testes escritos garantem que o que foi implementado está realmente funcionando? Faça testes que façam sentido para o contexto da tarefa, eles devem cobrir os fluxos da funcionalidade, desde o caminho feliz até caminhos de erro. Garanta que os testes de fato testem algo.
- A solução empregada foi a melhor para o momento? Lembre-se de aplicar técnicas de Clean Code, de refletir sobre a necessidade de se utilizar algo, como diz o YAGNI (You ain't gonna need it - Você ainda não vai precisar disso) e pense também na arquitetura utilizada.
Agilidade ¶
Agilidade não é necessariamente sobre fazer SCRUM, devemos falar mais sobre o manifesto!
"Indivíduos e interações mais que processos e ferramentas"
"Software funcionando é a primeira métrica de progresso"
"Atenção contínua para excelência técnica e um bom design aumenta a agilidade"
"As melhores arquiteturas, requisitos e designs emergem de times auto organizáveis"
Danger - uma ferramenta para melhorar o Code Review ¶
O Vinícius ainda citou o Danger, uma ferramenta que verifica se a documentação foi atualizada junto com o PR além de várias outras funcionalidades, rejeitando automaticamente PRs que não passem nessas regras estabelecidas.
Conclusões ¶
- Code review traz muitos benefícios para sua equipe que vão além de código, como entendimento das regras de negócio, alinhamento entre os membros.
- Devemos focar no que a máquina não pode fazer. A máquina consegue verificar estilo de código, PSRs, complexidade ciclomática, etc. Porém ela não consegue avaliar se um requisito foi atendido, por exemplo, e é nisso que podemos focar.
- Para a prática acontecer de maneira saudável precisamos de indivíduos motivados a melhorar, que saibam escutar as possíveis melhorias e queiram evoluir.
Veja os slides da apresentação clicando aqui.
Projetando Software Orientado a Objetos Com Qualidade - Marcel dos Santos ¶
Acabei por ficar um tempo conversando com o Júnior Grossi e o David Jonas sobre trabalho remoto e infelizmente não consegui assistir ao outro painel do evento, sobre a participação das mulheres na TI. Assim, acabei voltando para essa talk do Marcel.
O Marcel, que é desenvolvedor Web Full-Stack e um dos evangelistas do PHPSP, começa sua talk perguntando à plateia: "Orientação a Objetos? O que é isso?" e após algumas respostas, define: trata da comunicação entre objetos através da troca de mensagens. Um objeto tem características, comportamentos e o estado atual.
Pilares da Orientação a Objetos ¶
Os pilares da orientação a objetos são a abstração, que permite a representação da vida real dentro do sistema; a herança, que possibilita o reaproveitamento de código em que uma classe herda características e atributos de uma classe base; o encapsulamento, que permite ocultar a implementação interna de um objeto e o polimorfismo, que consiste na alteração do funcionamento interno de um método herdado do pai.
Coesão e acoplamento ¶
A coesão indica o grau de relação entre os membros de um módulo. Já o acoplamento é o grau de dependência entre as classes.
Os maus cheiros do projeto ¶
- Rigidez é a tendência do software de ser difícil de alterar, mesmo de maneira simples.
- Fragilidade é a tendência de uma única alteração estragar o software em muitos lugares.
- Imobilidade mostra que a separação de uma lógica pode ser muito custosa e inviabilizada.
- Viscosidade é uma característica que diz o quão difícil é de preservar um software.
- Complexidade desnecessária é quando existem elementos que não serão úteis no momento.
- Repetição desnecessária é quando um mesmo código aparece inúmeras vezes de forma pouco diferentes.
- Opacidade refere-se a dificuldade de compreensão de um módulo.
Princípios e práticas ¶
O SOLID é conjunto de princípios que permite um melhor projeto de sistemas.
No SOLID, temos a inversão de dependência: módulos de alto nível não devem
depender de módulos de baixo nível; módulos de alto nível devem depender apenas
de abstrações. módulos de baixo nível também devem depender apenas de
abstrações. Por exemplo, uma Classe A (alto nível) referencia uma Classe B
(baixo nível), ou seja, a A depende da B. Alterações em qualquer uma das
classes pode levar a efeitos indesejados na outra também. Utilizando-se uma
interface, a Classe B poderia implementá-la e a Classe A depender somente da
interface, tendo a garantia de que suas dependências estejam implementadas. Uma
iniciativa como essa diminui o acoplamento do nosso código. Utilizando
injeção de dependência, conseguimos alcançar o princípio da inversão de
dependência. É possível fazer isso sem a necessidade de bibliotecas.
Value Objects é outro conceito que o Marcel traz, que nada mais são que
objetos simples e pequenos em que a igualdade não é baseada em identidade,
ajudando a representar uma linguagem ubíqua no seu código. Por exemplo, ao
invés de representar um email como uma simples string, podemos ter uma classe
Email que poderia ter suas próprias garantias para dizer que o mesmo é válido,
dando maior segurança de transitar essa informação de email pelo sistema. O
mesmo vale também para um value object Money, por exemplo. É interessante se
utilizar o conceito quando os tipos possuem validação, regras de negócio
ou comportamento.
O princípio Tell, Don't Ask diz: não peça informações para fazer o seu trabalho, apenas diga o que quer que seja feito e deixe o outro objeto lidar com isso internamente.
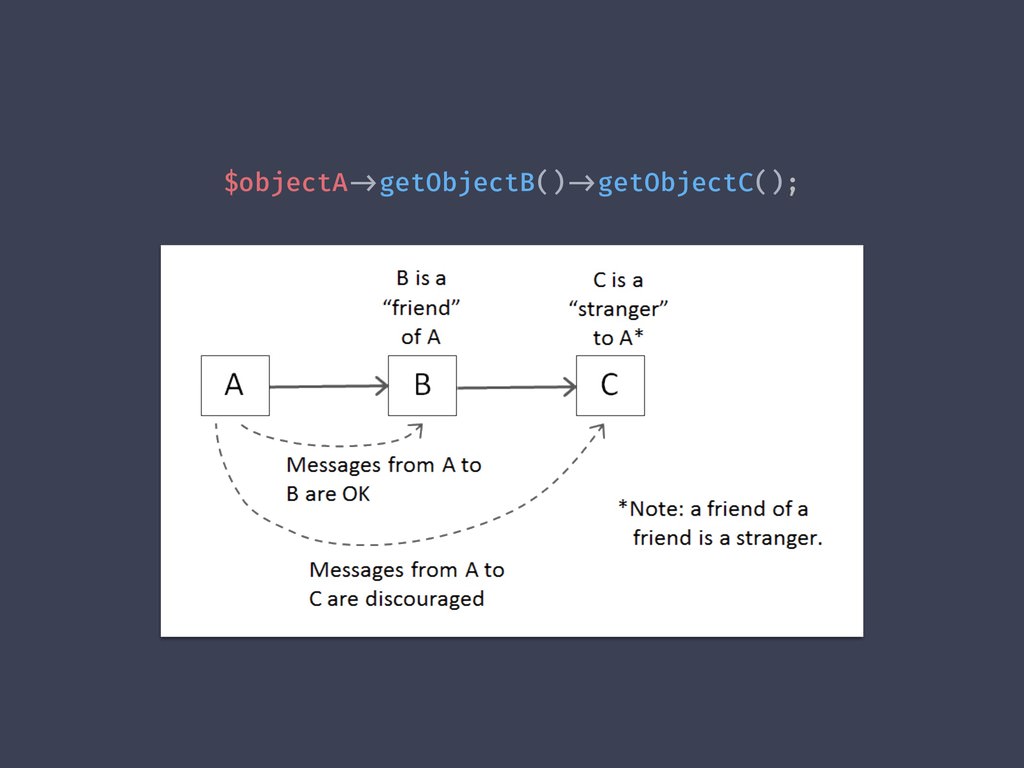
Já a Lei de Demeter diz: fale com seus amigos mais próximos, não fale com
estranhos. Por exemplo, tendo Classe A dependendo da Classe B e a B
dependendo da Classe C, a Classe A não deveria enviar mensagens diretamente
para a C, somente para a B.
Objects Calisthenics são um conjunto de nove exercícios que ajudam a melhorar a qualidade do seu código. O Marcel fez uma talk específica sobre esses exercícios na Laraconf Brazil 2017, confiram aqui.
Conclusões ¶
Os princípios de design ajudam a projetar códigos melhores. Um código mau projeto é um código difícil de mudar. Uma classe não deve ser forçada a depender de uma implementação específica. Uma classe deve depender de um contrato, abstração ou interface. Prefira classes com alta coesão e baixo acoplamento.
Nos slides, o Marcel deixa várias referências para se aprofundar no assunto.
Do legado ao DDD - Leonn Leite ¶
Para fechar as talks do dia - e também do evento, escolhi ver o Leonn, Líder Técnico PHP na Engesoftware e sua palestra sobre Domain-Driven Design (DDD).
Motivação - Código Legado ¶
Segundo o Leonn, Brasília é o país do legado, então fazer integração contínua em legado é perigoso. Assim, os problemas vão sendo replicados cada vez mais conforme o projeto vai sendo desenvolvido, ficando muito difícil de manter. Geralmente as aplicações são estruturadas. Quando se tem Orientação a Objeto, que é raro, muitas vezes é um OO estruturado, com métodos de mais de mil linhas.
Os testes das aplicações são feitos por humanos, sem nada automatizado. Testes unitários, por exemplo, não existem pois os contratos com governos não exigem e "se não pagam, não fazemos". Sobre reutilização de código, basicamente é Ctrl+C e Ctrl+V do Stack Overflow. Composer com Satis ou Toran Proxy poderiam ser utilizados para reaproveitar código...
A culpa desses sistemas serem assim geralmente é da falta de tempo, da experiência dos profissionais e de falhas na comunicação. Para lidar com a falta de tempo, o Leonn recomenda: não reinvente a roda; foque no problema real e não em "perfumarias". Sobre a experiência dos profissionais: faça pair programming, fale (literalmente) seus problemas, leia mais código, faça code review, leia código do GitHub.A falha na comunicação geralmente ocorre pelo medo de perguntar, pelo fato de cada um falar de uma forma diferente e, às vezes, quando tentamos programar em inglês, fica mais complexo e pode gerar dificuldade de entendimento.
O Leonn deixou também uma reflexão de um pré evento do PHP Experience:
"Vocês ainda não perceberam que o poder da empresa está na mão do programador?"
Tiago Baeta (cofundador do iMasters)
Entendendo sua aplicação ¶
O Leonn mostrou um exemplo de código, que, embora funcionasse, tinha alguns problemas: era desorganizado; com quase nenhuma verificação de erros; a reutilização só era possível copiando o código; a manutenção e os testes eram difíceis. Assim, duas opções surgiam para esse código: jogar fora e criar novo código do zero ou refatorar.
Sobre Views, devemos entender que é uma camada que não tem inteligência, só
imprime dados. E que também JSON é view, XML é view, HTML é view. Um
Front Controller faz o meio de campo, controla as requisições, coordena os
serviços, iniciada todas as jogadas. Um Service faz chamadas externas, faz a
transição do controller para o domínio, orquestra as operações do domínio,
porém regras de negocio não deveriam estar presentes nessa camada. Value
Objects são objetos que encapsulam tipos primitivos, por exemplo, Dinheiro,
Email (como o Marcel disse na talk dele), representam valores e são imutáveis.
Uma dica é a biblioteca moneyphp/money.
Entities também são objetos, possuem um identificador que não deve mudar,
são mutáveis e podem possuir Value Objects. Por fim, um Repository é uma
coleção, consiste de uma camada de persistência, pode ser In/Out e é usado
para inversão de dependência, a letra D do SOLID (algo que o Marcel comentou
também).
O que é DDD? ¶
Criado pelo Eric Evans, O Domain-Driven Design tem como subtítulo: "Atacando as complexidades no coração do software". Temos nosso Core Domain, que é nosso diferencial estratégico. Nosso domínio é representado pelo core domain somado aos subdomains. Devemos nos questionar:
- Por que escrever esse software vale a pena?
- Por que não comprar uma solução pronta?
- Por que não terceirizar o desenvolvimento?
Se você pode terceirizar, talvez essa parte do seu sistema não é o seu Core Domain. Nem sempre ele é o que aparenta ser.
Entre os subdomínios, temos os genéricos e os de suporte. Os genéricos são partes da aplicação que podem ser constituídos de projetos open source, pagos ou até mesmo terceirizados. Em contrapartida, os subdomínios de suporte são aqueles que não são diferenciais mas que são necessários, como por exemplo, módulos de pagamento no ecommerce ou módulos de autenticação. Uma dica para diferenciar é: "Eu não consigo viver sem o suporte, eu consigo adaptar o genérico".
O importante é focar esforços no Core Domain e evitar a IVSF, a "irresistível vontade de sair fazendo".
Sobre comunicação, o Leonn afirma: comunicação ruim é igual a código ruim. Portanto, tenha uma linguagem ubíqua: todos os envolvidos no projeto, não só desenvolvedores, falam nesses termos, todos devem saber o que cada termo significa e temos que usar os termos dos especialistas do domínio mesmo no nosso código.
As vezes os contextos devem ser separados e temos que fazer essa segmentação no código também, são os chamados Contextos Delimitados.
Conclusões ¶
O caminho, que não é uma solução única, mas uma dica do Leonn é: não desenvolva
baseado em framework; seja independente de storage (banco de dados, cache,
mecanismo de busca); use final class para ninguém estender o domínio,
ActiveRecord não deve ser usado. Use Eventos. Cuidado com Models
anêmicos, que tenham somente setters e getters. Em Models ricos, não
temos setters, os dados são passados apenas no construtor, a regra de negócio é
na entidade e segue o mundo real. CommandBus é uma técnica boa para trabalhar
com DDD. Saia da zona de conforto.
Confira os slides da talk do Leonn no SlideShare, tá cheio de referências.
Com isso, chegamos ao fim do Darkmira Tour que rolou em 2018. Espero estar presente no de 2020 e fazer a cobertura para vocês! 😉
Este artigo foi publicado originalmente no site do Ravan Scafi.